Optimizing Backstage Entity Ingestion
We are facing major rate limiting issues during the Backstage Entity Ingestion and Refresh Loop process. With around 10,000 active repositories, managing all Backstage Entities is overloading GitHub, causing too many requests per second.
Various discussions have taken place on Backstage Discord about this issue and potential solutions. We’ve compiled the majority of these ideas and evaluated them against our problem.
Some of these solutions offer short-term relief, while others provide more sustainable long-term strategies. Below, we outline the various approaches we considered and their potential impacts on alleviating the rate limiting problems:
Possible Solution Approaches:
- Centralized catalog
- Increase setProcessingIntervalSeconds
- Different Github AppID for Ingestion and Scaffolder or per instance
- Event Based Entity Providers
- Incremental Entity Provider
Centralized catalog
With a centralized catalog and grouped entities, the number of network requests required to access different entities is minimized. Instead of making multiple requests to fetch individual files or resources, the system can make fewer requests to fetch larger groups of entities. This reduction in network requests can help alleviate rate limit issues, as the system is making fewer requests within the rate limit constraints.
Centralize catalog example — https://github.com/codesandtags/backstage-huge-catalog/tree/main/centralized
Pros:
- Fewer network calls during ingestion and processing.
Cons:
- Complex implementation requiring changes in the majority of component repositories.
Increase setProcessingIntervalSeconds
This determines how frequently entities (once ingested) should be processed. If the interval is too low, it might exceed request quotas for upstream services.
When you increase the time between updates, it means that changes or new data will take longer to appear in the system. This delay is called “ingestion latency.” However, keep in mind that this solution only extends the interval, the overall volume of requests remains unchanged.
Pros:
- Short-Term Solution: Useful for companies ingesting fewer entities via a discovery method.
- Ideal for Small Scale: If you have fewer than 5,000 locations, set the processing interval to 60 minutes to manage API rate limits.
Cons:
- Ingestion Latency: Increasing the processing interval leads to longer delays in reflecting changes or new data. This can impact user experience.
Unique Github AppID per instance OR for Ingestion and Scaffolder
When you deploy multiple instances of Backstage, each instance tries to fetch locations from GitHub.Although the total number of requests remains the same, the time it takes for these requests to reach GitHub is significantly reduced, often triggering API rate limits.
To address this issue, consider allowing ingestion and processing work to be handled by a specific instance.
- In this scenario, only that particular instance would be responsible for issuing GitHub requests for ingestion and processing.
- While the number of requests remains unchanged, fetching the data will now take more time.
- It’s worth noting that GitHub refills the API token quota every hour
Event Based Providers
Event based providers work on the principle of Push model. Wherein every change in the entity is directly broadcasted to EntityProvider using webhook. It remove the requirement of updating all the entities after a scheduled interval. Instead it ingest real time entities and provides better user experience.
Pros:
- Default Solution: Useful for any company ingesting datasets of less then 50K. After 50k chances are you will face out-of-memory issue.
- Ready to use provider available directly inside Backstage
Cons:
- Need to enable Webhook support in version control systems
Incremental Entity Provider
When you are working in a large organisation where you have massive datasets and you are getting out-of-memory errors while doing the full mutation then this approach would be the right one for you.
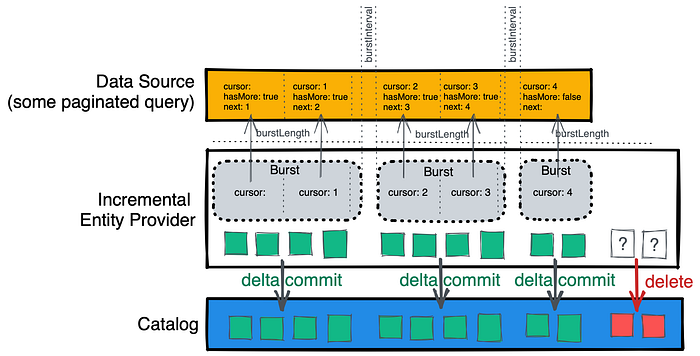
In this approach full mutation is done using a series of small delta mutations. It pauses ingestion after every few seconds to give the processing loop time to process existing entities. you can read more on it here.
Pros:
- Long-Term Solution: Useful for Enterprise companies ingesting Large dataset.
Cons:
- Ingestion Latency: Small increase in the processing interval as its pausing in between to combat memory issue.
- Complex implementation
Final Solution
There isn’t a one-size-fits-all solution, but we believe most of us can resolve the rate limiting issue with an Event-based ingestion strategy.
Event-based providers are readily available in Backstage with decent documentation, making implementation easier. This solution also covers a wide range of companies, from small to mid-sized, and will work for you as your data grows, giving you time to plan an incremental ingestion strategy.
References
https://backstage.io/blog/2023/01/31/incremental-entity-provider/#entity-providers
https://discord.com/channels/687207715902193673/687235481154617364/1141939965698256997
https://discord.com/channels/687207715902193673/687235481154617364/threads/1141940620940816496
https://github.com/backstage/backstage/issues/18866
https://frontside.com/blog/2022-05-03-backstage-entity-provider/
https://discord.com/channels/687207715902193673/1139571628133593119/1139617542550323321
https://discord.com/channels/687207715902193673/1238121923620245545/1243142343746654370
https://discord.com/channels/687207715902193673/1328659424331436045